
Joy Buolamwini is a graduate researcher at the MIT Media Lab and founder of the Algorithmic Justice League – an organisation that aims to challenge the biases in decision-making software. She grew up in Mississippi, gained a Rhodes scholarship, and she is also a Fulbright fellow, an Astronaut scholar and a Google Anita Borg scholar. Earlier this year she won a $50,000 scholarship funded by the makers of the film Hidden Figures for her work fighting coded discrimination.
A lot of your work concerns facial recognition technology. How did you become interested in that area?
When I was a computer science undergraduate I was working on social robotics – the robots use computer vision to detect the humans they socialise with. I discovered I had a hard time being detected by the robot compared to lighter-skinned people. At the time I thought this was a one-off thing and that people would fix this.
Later I was in Hong Kong for an entrepreneur event where I tried out another social robot and ran into similar problems. I asked about the code that they used and it turned out we’d used the same open-source code for face detection – this is where I started to get a sense that unconscious bias might feed into the technology that we create. But again I assumed people would fix this.
So I was very surprised to come to the Media Lab about half a decade later as a graduate student, and run into the same problem. I found wearing a white mask worked better than using my actual face.
This is when I thought, you’ve known about this for some time, maybe it’s time to speak up.
How does this problem come about?
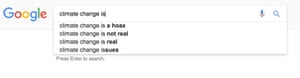
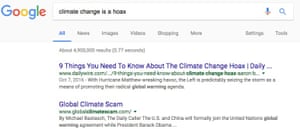
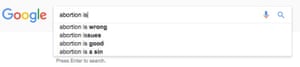
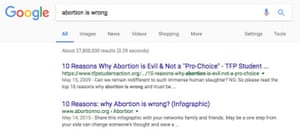
Within the facial recognition community you have benchmark data sets which are meant to show the performance of various algorithms so you can compare them. There is an assumption that if you do well on the benchmarks then you’re doing well overall. But we haven’t questioned the representativeness of the benchmarks, so if we do well on that benchmark we give ourselves a false notion of progress.
When we look at it now it seems very obvious, but with work in a research lab, I understand you do the “down the hall test” – you’re putting this together quickly, you have a deadline, I can see why these skews have come about. Collecting data, particularly diverse data, is not an easy thing.
Outside of the lab, isn’t it difficult to tell that you’re discriminated against by an algorithm?
Absolutely, you don’t even know it’s an option. We’re trying to identify bias, to point out cases where bias can occur so people can know what to look out for, but also develop tools where the creators of systems can check for a bias in their design.
Instead of getting a system that works well for 98% of people in this data set, we want to know how well it works for different demographic groups. Let’s say you’re using systems that have been trained on lighter faces but the people most impacted by the use of this system have darker faces, is it fair to use that system on this specific population?
Georgetown Law recently found that one in two adults in the US has their face in the facial recognition network. That network can be searched using algorithms that haven’t been audited for accuracy. I view this as another red flag for why it matters that we highlight bias and provide tools to identify and mitigate it.
Besides facial recognition what areas have an algorithm problem?
The rise of automation and the increased reliance on algorithms for high-stakes decisions such as whether someone gets insurance of not, your likelihood to default on a loan or somebody’s risk of recidivism means this is something that needs to be addressed. Even admissions decisions are increasingly automated – what school our children go to and what opportunities they have. We don’t have to bring the structural inequalities of the past into the future we create, but that’s only going to happen if we are intentional.
If these systems are based on old data isn’t the danger that they simply preserve the status quo?
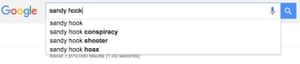
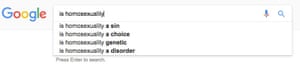
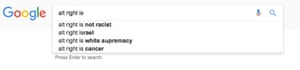
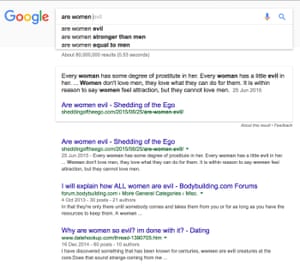
Absolutely. A study on Google found that ads for executive level positions were more likely to be shown to men than women – if you’re trying to determine who the ideal candidate is and all you have is historical data to go on, you’re going to present an ideal candidate which is based on the values of the past. Our past dwells within our algorithms. We know our past is unequal but to create a more equal future we have to look at the characteristics that we are optimising for. Who is represented? Who isn’t represented?
Isn’t there a counter-argument to transparency and openness for algorithms? One, that they are commercially sensitive and two, that once in the open they can be manipulated or gamed by hackers?
I definitely understand companies want to keep their algorithms proprietary because that gives them a competitive advantage, and depending on the types of decisions that are being made and the country they are operating in, that can be protected.
When you’re dealing with deep neural networks that are not necessarily transparent in the first place, another way of being accountable is being transparent about the outcomes and about the bias it has been tested for. Others have been working on black box testing for automated decision-making systems. You can keep your secret sauce secret, but we need to know, given these inputs, whether there is any bias across gender, ethnicity in the decisions being made.
Thinking about yourself – growing up in Mississippi, a Rhodes Scholar, a Fulbright Fellow and now at MIT – do you wonder that if those admissions decisions had been taken by algorithms you might not have ended up where you are?
If we’re thinking likely probabilities in the tech world, black women are in the 1%. But when I look at the opportunities I have had, I am a particular type of person who would do well. I come from a household where I have two college-educated parents – my grandfather was a professor in school of pharmacy in Ghana – so when you look at other people who have had the opportunity to become a Rhodes Scholar or do a Fulbright I very much fit those patterns. Yes, I’ve worked hard and I’ve had to overcome many obstacles but at the same time I’ve been positioned to do well by other metrics. So it depends on what you choose to focus on – looking from an identity perspective it’s as a very different story.
In the introduction to Hidden Figures the author Margot Lee Shetterly talks about how growing up near Nasa’s Langley Research Center in the 1960s led her to believe that it was standard for African Americans to be engineers, mathematicians and scientists…
That it becomes your norm. The movie reminded me of how important representation is. We have a very narrow vision of what technology can enable right now because we have very low participation. I’m excited to see what people create when it’s no longer just the domain of the tech elite, what happens when we open this up, that’s what I want to be part of enabling.
Absolutely, you don’t even know it’s an option. We’re trying to identify bias, to point out cases where bias can occur so people can know what to look out for, but also develop tools where the creators of systems can check for a bias in their design.
Instead of getting a system that works well for 98% of people in this data set, we want to know how well it works for different demographic groups. Let’s say you’re using systems that have been trained on lighter faces but the people most impacted by the use of this system have darker faces, is it fair to use that system on this specific population?
Georgetown Law recently found that one in two adults in the US has their face in the facial recognition network. That network can be searched using algorithms that haven’t been audited for accuracy. I view this as another red flag for why it matters that we highlight bias and provide tools to identify and mitigate it.
Besides facial recognition what areas have an algorithm problem?
The rise of automation and the increased reliance on algorithms for high-stakes decisions such as whether someone gets insurance of not, your likelihood to default on a loan or somebody’s risk of recidivism means this is something that needs to be addressed. Even admissions decisions are increasingly automated – what school our children go to and what opportunities they have. We don’t have to bring the structural inequalities of the past into the future we create, but that’s only going to happen if we are intentional.
If these systems are based on old data isn’t the danger that they simply preserve the status quo?
Absolutely. A study on Google found that ads for executive level positions were more likely to be shown to men than women – if you’re trying to determine who the ideal candidate is and all you have is historical data to go on, you’re going to present an ideal candidate which is based on the values of the past. Our past dwells within our algorithms. We know our past is unequal but to create a more equal future we have to look at the characteristics that we are optimising for. Who is represented? Who isn’t represented?
Isn’t there a counter-argument to transparency and openness for algorithms? One, that they are commercially sensitive and two, that once in the open they can be manipulated or gamed by hackers?
I definitely understand companies want to keep their algorithms proprietary because that gives them a competitive advantage, and depending on the types of decisions that are being made and the country they are operating in, that can be protected.
When you’re dealing with deep neural networks that are not necessarily transparent in the first place, another way of being accountable is being transparent about the outcomes and about the bias it has been tested for. Others have been working on black box testing for automated decision-making systems. You can keep your secret sauce secret, but we need to know, given these inputs, whether there is any bias across gender, ethnicity in the decisions being made.
Thinking about yourself – growing up in Mississippi, a Rhodes Scholar, a Fulbright Fellow and now at MIT – do you wonder that if those admissions decisions had been taken by algorithms you might not have ended up where you are?
If we’re thinking likely probabilities in the tech world, black women are in the 1%. But when I look at the opportunities I have had, I am a particular type of person who would do well. I come from a household where I have two college-educated parents – my grandfather was a professor in school of pharmacy in Ghana – so when you look at other people who have had the opportunity to become a Rhodes Scholar or do a Fulbright I very much fit those patterns. Yes, I’ve worked hard and I’ve had to overcome many obstacles but at the same time I’ve been positioned to do well by other metrics. So it depends on what you choose to focus on – looking from an identity perspective it’s as a very different story.
In the introduction to Hidden Figures the author Margot Lee Shetterly talks about how growing up near Nasa’s Langley Research Center in the 1960s led her to believe that it was standard for African Americans to be engineers, mathematicians and scientists…
That it becomes your norm. The movie reminded me of how important representation is. We have a very narrow vision of what technology can enable right now because we have very low participation. I’m excited to see what people create when it’s no longer just the domain of the tech elite, what happens when we open this up, that’s what I want to be part of enabling.









{kind=link}
{kind=link}