Ben Tarnoff in The Guardian
What if a cold drink cost more on a hot day?
Customers in the UK will soon find out. Recent reports suggest that three of the country’s largest supermarket chains are rolling out surge pricing in select stores. This means that prices will rise and fall over the course of the day in response to demand. Buying lunch at lunchtime will be like ordering an Uber at rush hour.
This may sound pretty drastic, but far more radical changes are on the horizon. About a week before that report, Amazon announced its $13.7bn purchase of Whole Foods. A company that has spent its whole life killing physical retailers now owns more than 460 stores in three countries.
Amazon isn’t abandoning online retail for brick-and-mortar. Rather, it’s planning to fuse the two. It’s going to digitize our daily lives in ways that make surge-pricing your groceries look primitive by comparison. It’s going to expand Silicon Valley’s surveillance-based business model into physical space, and make money from monitoring everything we do.
Silicon Valley is an extractive industry. Its resource isn’t oil or copper, but data. Companies harvest this data by observing as much of our online activity as they can. This activity might take the form of a Facebook like, a Google search, or even how long your mouse hovers in a particular part of your screen. Alone, these traces may not be particularly meaningful. By pairing them with those of millions of others, however, companies can discover patterns that help determine what kind of person you are – and what kind of things you might buy.
These patterns are highly profitable. Silicon Valley uses them to sell you products or to sell you to advertisers. But feeding the algorithms that produce these patterns requires a steady stream of data. And while that data is certainly abundant, it’s not infinite.
A hundred years ago, you could dig a hole in Texas and strike oil. Today, fossil fuel companies have to build drilling platforms many miles offshore. The tech industry faces a similar fate. Its wildcat days are over: most of the data that lies closest to the surface is already claimed. Together, Facebook and Google receive a staggering 76% of online advertising revenue in the United States.
 An Amazon Go ‘smart’ store in Seattle. The company’s acquisition of Whole Foods signals a desire to fuse online surveillance with brick-and-mortar business. Photograph: Paul Gordon/Zuma Press / eyevine
An Amazon Go ‘smart’ store in Seattle. The company’s acquisition of Whole Foods signals a desire to fuse online surveillance with brick-and-mortar business. Photograph: Paul Gordon/Zuma Press / eyevine
To increase profits, Silicon Valley must extract more data. One method is to get people to spend more time online: build new apps, and make them as addictive as possible. Another is to get more people online. This is the motivation for Facebook’s Free Basics program, which provides a limited set of internet services for free in underdeveloped regions across the globe, in the hopes of harvesting data from the world’s poor.
But these approaches leave large reservoirs of data untapped. After all, we can only spend so much time online. Our laptops, tablets, smartphones, and wearables see a lot of our lives – but not quite everything. For Silicon Valley, however, anything less than total knowledge of its users represents lost revenue. Any unmonitored moment is a missed opportunity.
Amazon is going to show the industry how to monitor more moments: by making corporate surveillance as deeply embedded in our physical environment as it is in our virtual one. Silicon Valley already earns vast sums of money from watching what we do online. Soon it’ll earn even more money from watching what we do offline.
It’s easy to picture how this will work, because the technology already exists. Late last year, Amazon built a “smart” grocery store in Seattle. You don’t have to wait in a checkout line to buy something – you just grab it and walk out of the store. Sensors detect what items you pick up, and you’re charged when you leave.
Imagine if your supermarket watched you as closely as Facebook or Google
Amazon is keen to emphasize the customer benefits: nobody likes waiting in line to pay for groceries, or fumbling with one’s wallet at the register. But the same technology that automates away the checkout line will enable Amazon to track every move a customer makes.
Imagine if your supermarket watched you as closely as Facebook or Google does. It would know not only which items you bought, but how long you lingered in front of which products and your path through the store. This data holds valuable lessons about your personality and your preferences – lessons that Amazon will use to sell you more stuff, online and off.
Supermarkets aren’t the only places these ideas will be put into practice. Surveillance can transform any physical space into a data mine. And the most data-rich environment, the one that contains the densest concentration of insights into who you are, is your home.
That’s why Amazon has aggressively promoted the Echo, a small speaker that offers a Siri-like voice-activated assistant called Alexa. Alexa can tell you the weather, read you the news, make you a to-do list, and perform any number of other tasks. It is a very good listener. It faithfully records your interactions and transmits them back to Amazon for analysis. In fact, it may be recording not only your interactions, but absolutely everything.
Putting a listening device in your living room is an excellent way for Amazon to learn more about you. Another is conducting aerial surveillance of your house. In late July, Amazon obtained a patent for drones that spy on people’s homes as they make deliveries. An example included in Amazon’s patent filing is roof repair: the drone that drops a package on your doorstep might notice your roof is falling apart, and that observation could result in a recommendation for a repair service. Amazon is still testing its delivery drones. But if and when they start flying, it’s safe to assume they’ll be scraping data from the outside of our homes as diligently as the Echo does from the inside.

Silicon Valley is an extractive industry. Its resource isn’t oil or copper, but data. And to increase profits, Silicon Valley must extract more. Photograph: Spencer Platt/Getty Images
Amazon is likely to face some resistance as it colonizes more of our lives. People may not love the idea of their supermarkets spying on them, or every square inch of their homes being fed to an algorithm. But one should never underestimate how rapidly norms can be readjusted when capital requires it.
A couple of decades ago, letting a company read your mail and observe your social interactions and track your location would strike many, if not most, as a breach of privacy. Today, these are standard, even banal, aspects of using the internet. It’s worth considering what further concessions will come to feel normal in the next 20 years, as Silicon Valley is forced to dig deeper into our lives for data.
Tech’s apologists will say that consumers can always opt out: if you object to a company’s practices, don’t use its services. But in our new era of monopoly capitalism, consumer choice is a meaningless concept. Companies like Google and Facebook and Amazon dominate the digital sphere – you can’t avoid them.
The only solution is political. As consumers we’re nearly powerless, but as citizens, we can demand more democratic control of our data. Data is a common good. We make it together, and we make it meaningful together, since useful patterns only emerge from collecting and analyzing large quantities of it.
No reasonable person would let the mining industry unilaterally decide how to extract and refine a resource, or where to build its mines. Yet somehow we let the tech industry make all these decisions and more, with practically no public oversight. A company that yanks copper out of an earth that belongs to everyone should be governed in everyone’s interest. So should a company that yanks data out of every crevice of our collective lives.
Tim Adams in The Guardian
In 1861 a shopkeeper in Philadelphia revolutionised the retail industry. John Wanamaker, who opened his department store in a Quaker district of the city, introduced price tags for his goods, along with the high-minded slogan: “If everyone was equal before God, then everyone would be equal before price.” The practice caught on. Up until then high-street retailers had generally operated a market-stall system of haggling on most products. Their best prices might be reserved for their best customers. Or they would weigh up each shopper and make a guess at what they could afford to pay and eventually come to an agreement.
Wanamaker’s idea was not all about transparency, however. Fixed pricing changed the relationship between customer and store in fundamental ways. It created the possibilities of price wars, loss leaders, promotional prices and sales. For the first time people were invited to enter stores without the implied obligation to buy anything (until then shops had been more like restaurants; you went in on the understanding that you wouldn’t leave without making a purchase). Now customers could come in and look and wander and perhaps be seduced. Shopping had been invented.
If you have enough data you can get closer to the ideal of giving your customers what they want at the time they want it - Roy Horgan, Market Hub CEO
For the last 150 years or so, Wanamaker’s fixed-price principle has been a norm on the high street. Shoppers might expect the price of bread or fish or vegetables to go down at the end of a day, or when they neared a sell-by date, but they would not expect prices to fluctuate very often on durable goods, and they would never expect the person behind them in the queue to be offered a different price to the one they were paying. That idea is no longer secure. Technology, for better and worse, through the appliance of big data and machine intelligence, can now transport us back to the shopping days of before 1861.
The notion of “dynamic pricing” has long been familiar to anyone booking a train ticket, a hotel room or holiday (Expedia might offer thousands of price changes for an overnight stay in a particular location in a single day). We are used to prices fluctuating hour by hour, apparently according to availability. Uber, meanwhile, has introduced – and been criticised for – “surge pricing”, making rapid adjustments to the fares on its platform in response to changes in demand. During the recent tube strikes in London, prices for cab journeys ‘automatically” leapt 400%. (The company argued that by raising fares it was able to encourage more taxi drivers to take to the streets during busy times, helping the consumer.)
What we are less aware of is the way that both principles have also invaded all aspects of online retailing – and that pricing policies are not only dependent on availability or stock, but also, increasingly, on the data that has been stored and kept about your shopping history. If you are an impulse buyer, or a full-price shopper or a bargain hunter, online retailers are increasingly likely to see you coming. Not only that: there is evidence to suggest that calculations about what you will be prepared to pay for a given product are made from knowledge of your postcode, who your friends are, what your credit rating looks like and any of the thousands of other data points you have left behind as cookie crumbs in your browsing history.
Facebook has about 100 data points on each of its 2 billion users, generally including the value of your home, your regular outgoings and disposable income – the kind of information that bazaar owners the world over might have once tried to intuit. Some brokerage firms offering data to retailers can provide more than 1,500 such points on an individual. Even your technology can brand you as a soft touch. The travel site Orbitz made headlines when it was revealed to have calculated that Apple Mac users were prepared to pay 20-30% more for hotel rooms than users of other brands of computer, and to have adjusted its pricing accordingly.
The algorithms employed by Amazon, with its ever-growing user database, and second-by-second sensitivity to demand, are ever more attuned to our habits and wishes. Websites such as camelcamelcamel.com allow to you monitor the way that best-buy prices on the site fluctuate markedly hour by hour. I watched the price of a new vacuum cleaner I had my eye on – the excitement! – waver like the graph of a dodgy penny stock last week. What is so far less certain is whether those price changes are ever being made just for you. (Amazon insists its price changes are never attempts to gather data on customers’ spending habits, but rather to give shoppers the lowest price available.)
Until quite recently this facility to both monitor the market and give consumers best price offers has looked like another advantage of the digital retailer over its bricks and mortar counterpart. Recently there have been efforts to address that inequality and replicate the possibilities of dynamic pricing on the high street.
Ever since data has been collected on customer purchases it has been possible to place shoppers into what analysts call “different consumer buckets”: impulse shoppers who were likely to buy sweets at the checkout counter; Fitbit obsessives willing to pay over the odds for organic kale. In her cheerily titled book Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy Cathy O’Neil notes how by 2013, as part of a research project by the consultant Accenture using data from a major retailer, “it was possible to estimate how much it would cost to turn each shopper from one brand of ketchup or coffee to another more profitable brand. The supermarket could then pick out, say, the 15% most likely to switch and provide them with coupons. Smart targeting was essential, [as] they didn’t want to give coupons to shoppers happy to pay full price.”
Dynamic pricing is familiar to users of online travel websites such as Expedia. Photograph: Alamy
The obstacle to creating such “smart” pricing strategies in store has been the stubbornness of the paper price tag. A price change in most British retailers still involves a laconic employee manually updating them. In that, the UK currently lags quite far behind its neighbours in Europe (a fact noted last year by Nick Boles, then minister for skills, who praised French retailers for having systems that could change prices “90,000 times a day” while we still had minimum-wage employees traipsing along the aisles). Electronic price tags, which allow those 90,000 dynamic price changes, are a fact of life in most larger stores not only in France, but also in Germany and Scandinavia.
Within a couple of years it is likely they will become the norm here too – not least because cheap “price gun” labour might be harder to come by for supermarkets post-Brexit. That is certainly the view of Roy Horgan, chief executive of a company called Market Hub, which not only offers electronic shelf labels but also data analysis to keep prices competitive. Market Hub was created in 2010 by Horgan in part as a response to what he saw as a “race to the bottom” by retailers in his native Ireland in response to the financial crash. “We just thought that this can’t be the way to compete,” he says. “One of the things we are sure of is if you are copying your competitors’ strategy and you are losing, then they are losing too…” There had to be a smarter way.
Earlier this year the French market leader SES took a majority share in Horgan’s firm, giving it access to 15,000 stores. Only two or three of those at the moment are in Britain – Spar stores in Walthamstow and Hackney in London, where they are experimenting with dynamic pricing in the food hall, particularly with bread. The retailers show not only an uplift in revenue and profit (of 2.5%), but also a drop in wasted food of around 30%, according to Market Hub. They are selling their products in part as an eco-efficient system that prevents waste.
“When we set out,” Horgan says, “there were literally hundreds of startups analysing where customers were going in the store, or whatever. But there was also a ‘so what?’ about that. It didn’t make any difference without the ability to execute price [changes] and to make that change at the shelf. We developed a piece of software called Pulse, which analyses sales, weight, stock, and competitors’ prices that allows you to basically decide or not decide to take a trade. A city centre store will want to catch customers at the end of the day before they head home, so what level do you set your price at?”
Horgan suggests that British retailers are still a bit terrified that customers will be put off by changing prices – they notice one shift in price of a loaf of bread, but don’t see 50 changes of price in the vacuum cleaner they are browsing on Amazon. He believes that the system can benefit both consumer and retailer though, because it is about getting the right deal. “If you have enough data you can get closer and closer to the ideal, which is giving your customers what they want and at the time they want it, rather than overwhelming them with deals.”
It also perhaps has the potential to offer a glimmer of hope for the beleaguered high street. Shops are all too aware of the habit of “showrooming”, by which customers look at products in stores before going home and browsing the best deals for them online. Electronic price-tag systems can not only track online prices, they can – and sometimes do – also display at point of sale the hidden cost of shipping if the same product was bought online – a cost that most online customers don’t factor in. “There is a way for [high street] retailers to become profitable again,” Horgan insists.
So far, such systems have not entered the murkier waters of using the data to offer different customers different prices for the same product at the same moment. A couple of years ago B&Q tested electronic price tags that display an item’s price based on who was looking at it, using data gathered from the customer’s mobile phone, in the hope, the store insisted, “of rewarding regular customers with discounts and special offers” – rather than identifying who might pay top price for a product based on their purchasing history.
That trial hasn’t become a widespread practice, although with the advent of electronic systems and the greater possibilities of using your phone apps as a means of payment, it is probably only a matter of time. Should such pricing policies alarm us? The problem, as with all data-based solutions, is that we don’t know – no one knows – exactly which “consumer bucket” we have been put in and precisely why. In 2012, a Wall Street Journal investigation discovered that online companies including the office-supply store Staples and the furniture retailer Home Depot showed customers different prices based on “a range of characteristics that could be discovered about the user”. How far, for example, a customer was from a bricks-and-mortar store was factored in for weighty items; customers in locations with a higher average income – and perhaps more buying choice – were generally shown lower prices. Another study, in Spain, showed that the price of the headphones Google recommends to you in its ads correlated with how budget-conscious your web history showed you to be.
Increasingly, there is no such thing as a fixed price from which sale items deviate. Following a series of court judgments against other retailers advertising bogus sale prices, Amazon has tended to drop most mentions of “list price” or recommended retail price, and use instead the reference point of its own past prices.
This looks a lot like the beginning of the end of John Wanamaker’s mission to establish “new, fair and most agreeable relations between the buyer and the seller” and to establish something closer to a comparison site that works both ways – we will be looking for the low-selling retailer, while the retailer will equally be scanning for the high-value customer. The old criticism that consumer societies know the price of everything and the value of nothing is under threat: even the former certainty is up for debate.
Store wars: the future of shopping
Vending machines 2.0

Smart-Vend-Solutions-facial-recognition-vending-machine-in-use
The Luxe X2 Touch features facial recognition software to identify users and suggest purchases based on spending history or context, such as iced drinks on a hot day. It can also prevent children from buying cigarettes or alcohol, or keep hospital patients away from sugary or salty foods.
The Amazon Go store

The Seattle store is the first to eliminate checkout lines by using a mobile app. Customers simply scan their smartphone on entry and pick up what they want. Computer vision technology keeps track of their purchases and their Amazon account is debited when they are finished.
Automated assistants

FacebookTwitterPinterest
US home improvement store Lowe is introducing a new employee into its workforce: a robot that finds products for you. The robots, which will start roaming the aisles in San Jose, California, during the course of the year, speak several languages and can answer customers’ questions.
Beacons of hope

FacebookTwitterPinterest
Beacons are small, battery-operated, wireless devices that transmit a bluetooth signal to an appropriate smartphone app. This technology can be used to nudge customers into the store, suggest offers and purchases, and also stores information to monitor customer behaviour.
The Starship delivery bot

FacebookTwitterPinterest Photograph: Starship Technologies/PA
Conceived by the founders of Skype, this is designed to deliver anything from groceries to books. The autonomous six-wheeled robot is speedy and saves you from lugging shopping bags, although it is questionable how safe it will be roaming the streets of Britain.
Pop-up shops

FacebookTwitterPinterest Photograph: Katy Dillon
Got an idea for a shop, but worried about the commitment of opening one? Appear Hear is a website that helps you find short-term retail space and is designed to connect retailers, entrepreneurs, brands and designers alike. It has so far been used by top brands including Nike and Moleskine.
Carole Cadwalldr in The Guardian
Is Brexit the will of the people? And if so, which people exactly? There are many disquieting questions to be asked about world events right now. But, in the week in which Theresa May received parliament’s approval to trigger article 50 and send us crashing out of the European Union, there are none more compelling and urgent than about the integrity of our entire democratic system.
The questions that remain unanswered are not about party infighting, and not even about Brexit. The issue is this: did foreign individuals or powers, acting covertly, subvert our democracy?
There are mounting and deeply disquieting questions about the role “dark money” may have played during last year’s EU referendum; and about whether the use of offshore jurisdictions, loopholes in European and North American data laws, undeclared foreign donors, a closed, all-powerful technological system (Facebook) and an antiquated and hopelessly out-of-touch oversight body has undermined the very foundations of our electoral system.
This is what we know: the Electoral Commission is still assessing claims that potentially illegal donations were made; the information commissioner is investigating “possible illegal” use of data; the heads of MI6 and GCHQ have both voiced unprecedented warnings about foreign interference in our democratic systems; the government has refused to elaborate on what these are; one of the leave campaigns has admitted the undeclared support and help of the American hedge fund billionaire who backed Trump; the Crown Prosecution Service is being asked to mount a criminal investigation; and questions have been raised about possible unlawful collaboration between different elements of the leave campaign.
And this all leads to the next question: are we really going to allow article 50 to be triggered when we don’t even know if the referendum was freely, fairly and legally conducted?
Even if you back Brexit, even if you can’t wait for Theresa May to pull the article 50 trigger, this should be the cause of serious concern. Yes, maybe this vote went the way you wanted. But what about the next?
MI6 and GCHQ have both voiced warnings about foreign interference in our democratic systems
This weekend brought two startling warnings from two entirely different quarters. The first from the man who invented the world wide web, Tim Berners-Lee, who said he was “extremely worried” about the future of democracy; that data harvesting was being used to “chilling” effect; that political targeting on the basis of it was “unethical”; and that the internet had been weaponised and was being used against us.
The second came from GCHQ, whose National Cyber Security Centre head has written to the main political parties warning of hostile interference. This was months after the head of the MI6, Alex Younger, made an unprecedented speech warning of “cyber attacks, propaganda or subversion of the democratic process”. And he added: “The risks at stake are profound and represent a fundamental threat to our sovereignty. They should be a concern to all those who share democratic values.”
Three months on, May’s government has refused to tell us what those risks are. What does Younger know? Why has parliament not been told? Who is investigating, and when will we know the results? Where is Dominic Grieve, the head of the intelligence select committee, in all this? And how can any of us have any trust in the democratic process when vital information is being kept from us?

Watchdog to launch inquiry into misuse of data in politics
We do know that Russian interests interfered in the US election. That has been catalogued by the National Security Agency, the CIA and the FBI. And that the beneficiary of that interference was Donald Trump. We know that Trump, his campaign strategist Steve Bannon, and the billionaire who funded his campaign, Robert Mercer, all have long-standing, close ties to Nigel Farage, Arron Banks and last year’s Leave.eu campaign. We know that the data company Cambridge Analytica, owned by Mercer and with Steve Bannon on the board, undertook work for Leave.eu.
We know that Cambridge Analytica’s parent company, SCL, employed a Canadian individual – Zackary Massingham – to undertake work for it. We know Massingham is a director of a company called AggregateIQ, and that Vote Leave – the official leave campaign – paid AggregateIQ £3.5m to do its profiling and Facebook advertising. We know it paid AggregateIQ a further £725,000 on behalf of two other organisations – one of which was a 23-year-old student who worked in Vote Leave’s office. And we know Northern Ireland’s Democraticlse we know: that the law demands that coordinated campaigns declare their expenditure and are subject to a strict combined limit. Yet here we see four different campaigns using the same tiny Canadian company based thousands of miles and seven time zones away. Coincidence? And this same company, AggregateIQ, has direct links (through Massingham) to the company used by the separate campaign Leave.eu.
However, we don’t know what contact, if any, there was between these five campaigns, or if employing a North American company (in a jurisdiction known for its far less stringent laws on both data protection and financial disclosure) had other benefits. But we do know that data is power: Facebook admitted last week that it can use data to swing elections – for the right price.
All the individuals and organisations deny any wrongdoing. But there are too many questions. There may be straightforward explanations but they have to be asked, addressed and answered.
If May triggers article 50 before we have those answers, we won’t know if Brexit is the will of the people or if it’s the result of a determined foreign actor, or actors, undermining our entire democratic system.
William Davies in The Guardian
In theory, statistics should help settle arguments. They ought to provide stable reference points that everyone – no matter what their politics – can agree on. Yet in recent years, divergent levels of trust in statistics has become one of the key schisms that have opened up in western liberal democracies. Shortly before the November presidential election, a study in the US discovered that 68% of Trump supporters distrusted the economic data published by the federal government. In the UK, a research project by Cambridge University and YouGov looking at conspiracy theories discovered that 55% of the population believes that the government “is hiding the truth about the number of immigrants living here”.
Rather than diffusing controversy and polarisation, it seems as if statistics are actually stoking them. Antipathy to statistics has become one of the hallmarks of the populist right, with statisticians and economists chief among the various “experts” that were ostensibly rejected by voters in 2016. Not only are statistics viewed by many as untrustworthy, there appears to be something almost insulting or arrogant about them. Reducing social and economic issues to numerical aggregates and averages seems to violate some people’s sense of political decency.
Nowhere is this more vividly manifest than with immigration. The thinktank British Future has studied how best to win arguments in favour of immigration and multiculturalism. One of its main findings is that people often respond warmly to qualitative evidence, such as the stories of individual migrants and photographs of diverse communities. But statistics – especially regarding alleged benefits of migration to Britain’s economy – elicit quite the opposite reaction. People assume that the numbers are manipulated and dislike the elitism of resorting to quantitative evidence. Presented with official estimates of how many immigrants are in the country illegally, a common response is to scoff. Far from increasing support for immigration, British Future found, pointing to its positive effect on GDP can actually make people more hostile to it. GDP itself has come to seem like a Trojan horse for an elitist liberal agenda. Sensing this, politicians have now largely abandoned discussing immigration in economic terms.
All of this presents a serious challenge for liberal democracy. Put bluntly, the British government – its officials, experts, advisers and many of its politicians – does believe that immigration is on balance good for the economy. The British government did believe that Brexit was the wrong choice. The problem is that the government is now engaged in self-censorship, for fear of provoking people further.
This is an unwelcome dilemma. Either the state continues to make claims that it believes to be valid and is accused by sceptics of propaganda, or else, politicians and officials are confined to saying what feels plausible and intuitively true, but may ultimately be inaccurate. Either way, politics becomes mired in accusations of lies and cover-ups.
The declining authority of statistics – and the experts who analyse them – is at the heart of the crisis that has become known as “post-truth” politics. And in this uncertain new world, attitudes towards quantitative expertise have become increasingly divided. From one perspective, grounding politics in statistics is elitist, undemocratic and oblivious to people’s emotional investments in their community and nation. It is just one more way that privileged people in London, Washington DC or Brussels seek to impose their worldview on everybody else. From the opposite perspective, statistics are quite the opposite of elitist. They enable journalists, citizens and politicians to discuss society as a whole, not on the basis of anecdote, sentiment or prejudice, but in ways that can be validated. The alternative to quantitative expertise is less likely to be democracy than an unleashing of tabloid editors and demagogues to provide their own “truth” of what is going on across society.
Is there a way out of this polarisation? Must we simply choose between a politics of facts and one of emotions, or is there another way of looking at this situation? One way is to view statistics through the lens of their history. We need to try and see them for what they are: neither unquestionable truths nor elite conspiracies, but rather as tools designed to simplify the job of government, for better or worse. Viewed historically, we can see what a crucial role statistics have played in our understanding of nation states and their progress. This raises the alarming question of how – if at all – we will continue to have common ideas of society and collective progress, should statistics fall by the wayside.
In the second half of the 17th century, in the aftermath of prolonged and bloody conflicts, European rulers adopted an entirely new perspective on the task of government, focused upon demographic trends – an approach made possible by the birth of modern statistics. Since ancient times, censuses had been used to track population size, but these were costly and laborious to carry out and focused on citizens who were considered politically important (property-owning men), rather than society as a whole. Statistics offered something quite different, transforming the nature of politics in the process.
Statistics were designed to give an understanding of a population in its entirety,rather than simply to pinpoint strategically valuable sources of power and wealth. In the early days, this didn’t always involve producing numbers. In Germany, for example (from where we get the term Statistik) the challenge was to map disparate customs, institutions and laws across an empire of hundreds of micro-states. What characterised this knowledge as statistical was its holistic nature: it aimed to produce a picture of the nation as a whole. Statistics would do for populations what cartography did for territory.
Equally significant was the inspiration of the natural sciences. Thanks to standardised measures and mathematical techniques, statistical knowledge could be presented as objective, in much the same way as astronomy. Pioneering English demographers such as William Petty and John Graunt adapted mathematical techniques to estimate population changes, for which they were hired by Oliver Cromwell and Charles II.
The emergence in the late 17th century of government advisers claiming scientific authority, rather than political or military acumen, represents the origins of the “expert” culture now so reviled by populists. These path-breaking individuals were neither pure scholars nor government officials, but hovered somewhere between the two. They were enthusiastic amateurs who offered a new way of thinking about populations that privileged aggregates and objective facts. Thanks to their mathematical prowess, they believed they could calculate what would otherwise require a vast census to discover.
There was initially only one client for this type of expertise, and the clue is in the word “statistics”. Only centralised nation states had the capacity to collect data across large populations in a standardised fashion and only states had any need for such data in the first place. Over the second half of the 18th century, European states began to collect more statistics of the sort that would appear familiar to us today. Casting an eye over national populations, states became focused upon a range of quantities: births, deaths, baptisms, marriages, harvests, imports, exports, price fluctuations. Things that would previously have been registered locally and variously at parish level became aggregated at a national level.
New techniques were developed to represent these indicators, which exploited both the vertical and horizontal dimensions of the page, laying out data in matrices and tables, just as merchants had done with the development of standardised book-keeping techniques in the late 15th century. Organising numbers into rows and columns offered a powerful new way of displaying the attributes of a given society. Large, complex issues could now be surveyed simply by scanning the data laid out geometrically across a single page.
These innovations carried extraordinary potential for governments. By simplifying diverse populations down to specific indicators, and displaying them in suitable tables, governments could circumvent the need to acquire broader detailed local and historical insight. Of course, viewed from a different perspective, this blindness to local cultural variability is precisely what makes statistics vulgar and potentially offensive. Regardless of whether a given nation had any common cultural identity, statisticians would assume some standard uniformity or, some might argue, impose that uniformity upon it.
Not every aspect of a given population can be captured by statistics. There is always an implicit choice in what is included and what is excluded, and this choice can become a political issue in its own right. The fact that GDP only captures the value of paid work, thereby excluding the work traditionally done by women in the domestic sphere, has made it a target of feminist critique since the 1960s. In France, it has been illegal to collect census data on ethnicity since 1978, on the basis that such data could be used for racist political purposes. (This has the side-effect of making systemic racism in the labour market much harder to quantify.)
Despite these criticisms, the aspiration to depict a society in its entirety, and to do so in an objective fashion, has meant that various progressive ideals have been attached to statistics. The image of statistics as a dispassionate science of society is only one part of the story. The other part is about how powerful political ideals became invested in these techniques: ideals of “evidence-based policy”, rationality, progress and nationhood grounded in facts, rather than in romanticised stories.
Since the high-point of the Enlightenment in the late 18th century, liberals and republicans have invested great hope that national measurement frameworks could produce a more rational politics, organised around demonstrable improvements in social and economic life. The great theorist of nationalism, Benedict Anderson, famously described nations as “imagined communities”, but statistics offer the promise of anchoring this imagination in something tangible. Equally, they promise to reveal what historical path the nation is on: what kind of progress is occurring? How rapidly? For Enlightenment liberals, who saw nations as moving in a single historical direction, this question was crucial.
The potential of statistics to reveal the state of the nation was seized in post-revolutionary France. The Jacobin state set about imposing a whole new framework of national measurement and national data collection. The world’s first official bureau of statistics was opened in Paris in 1800. Uniformity of data collection, overseen by a centralised cadre of highly educated experts, was an integral part of the ideal of a centrally governed republic, which sought to establish a unified, egalitarian society.
From the Enlightenment onwards, statistics played an increasingly important role in the public sphere, informing debate in the media, providing social movements with evidence they could use. Over time, the production and analysis of such data became less dominated by the state. Academic social scientists began to analyse data for their own purposes, often entirely unconnected to government policy goals. By the late 19th century, reformers such as Charles Booth in London and WEB Du Bois in Philadelphia were conducting their own surveys to understand urban poverty.
Illustration by Guardian Design
To recognise how statistics have been entangled in notions of national progress, consider the case of GDP. GDP is an estimate of the sum total of a nation’s consumer spending, government spending, investments and trade balance (exports minus imports), which is represented in a single number. This is fiendishly difficult to get right, and efforts to calculate this figure began, like so many mathematical techniques, as a matter of marginal, somewhat nerdish interest during the 1930s. It was only elevated to a matter of national political urgency by the second world war, when governments needed to know whether the national population was producing enough to keep up the war effort. In the decades that followed, this single indicator, though never without its critics, took on a hallowed political status, as the ultimate barometer of a government’s competence. Whether GDP is rising or falling is now virtually a proxy for whether society is moving forwards or backwards.
Or take the example of opinion polling, an early instance of statistical innovation occurring in the private sector. During the 1920s, statisticians developed methods for identifying a representative sample of survey respondents, so as to glean the attitudes of the public as a whole. This breakthrough, which was first seized upon by market researchers, soon led to the birth of the opinion polling. This new industry immediately became the object of public and political fascination, as the media reported on what this new science told us about what “women” or “Americans” or “manual labourers” thought about the world.
Nowadays, the flaws of polling are endlessly picked apart. But this is partly due to the tremendous hopes that have been invested in polling since its origins. It is only to the extent that we believe in mass democracy that we are so fascinated or concerned by what the public thinks. But for the most part it is thanks to statistics, and not to democratic institutions as such, that we can know what the public thinks about specific issues. We underestimate how much of our sense of “the public interest” is rooted in expert calculation, as opposed to democratic institutions.
As indicators of health, prosperity, equality, opinion and quality of life have come to tell us who we are collectively and whether things are getting better or worse, politicians have leaned heavily on statistics to buttress their authority. Often, they lean too heavily, stretching evidence too far, interpreting data too loosely, to serve their cause. But that is an inevitable hazard of the prevalence of numbers in public life, and need not necessarily trigger the type of wholehearted rejections of expertise that we have witnessed recently.
In many ways, the contemporary populist attack on “experts” is born out of the same resentment as the attack on elected representatives. In talking of society as a whole, in seeking to govern the economy as a whole, both politicians and technocrats are believed to have “lost touch” with how it feels to be a single citizen in particular. Both statisticians and politicians have fallen into the trap of “seeing like a state”, to use a phrase from the anarchist political thinker James C Scott. Speaking scientifically about the nation – for instance in terms of macroeconomics – is an insult to those who would prefer to rely on memory and narrative for their sense of nationhood, and are sick of being told that their “imagined community” does not exist.
On the other hand, statistics (together with elected representatives) performed an adequate job of supporting a credible public discourse for decades if not centuries. What changed?
The crisis of statistics is not quite as sudden as it might seem. For roughly 450 years, the great achievement of statisticians has been to reduce the complexity and fluidity of national populations into manageable, comprehensible facts and figures. Yet in recent decades, the world has changed dramatically, thanks to the cultural politics that emerged in the 1960s and the reshaping of the global economy that began soon after. It is not clear that the statisticians have always kept pace with these changes. Traditional forms of statistical classification and definition are coming under strain from more fluid identities, attitudes and economic pathways. Efforts to represent demographic, social and economic changes in terms of simple, well-recognised indicators are losing legitimacy.
Consider the changing political and economic geography of nation states over the past 40 years. The statistics that dominate political debate are largely national in character: poverty levels, unemployment, GDP, net migration. But the geography of capitalism has been pulling in somewhat different directions. Plainly globalisation has not rendered geography irrelevant. In many cases it has made the location of economic activity far more important, exacerbating the inequality between successful locations (such as London or San Francisco) and less successful locations (such as north-east England or the US rust belt). The key geographic units involved are no longer nation states. Rather, it is cities, regions or individual urban neighbourhoods that are rising and falling.
The Enlightenment ideal of the nation as a single community, bound together by a common measurement framework, is harder and harder to sustain. If you live in one of the towns in the Welsh valleys that was once dependent on steel manufacturing or mining for jobs, politicians talking of how “the economy” is “doing well” are likely to breed additional resentment. From that standpoint, the term “GDP” fails to capture anything meaningful or credible.
When macroeconomics is used to make a political argument, this implies that the losses in one part of the country are offset by gains somewhere else. Headline-grabbing national indicators, such as GDP and inflation, conceal all sorts of localised gains and losses that are less commonly discussed by national politicians. Immigration may be good for the economy overall, but this does not mean that there are no local costs at all. So when politicians use national indicators to make their case, they implicitly assume some spirit of patriotic mutual sacrifice on the part of voters: you might be the loser on this occasion, but next time you might be the beneficiary. But what if the tables are never turned? What if the same city or region wins over and over again, while others always lose? On what principle of give and take is that justified?
In Europe, the currency union has exacerbated this problem. The indicators that matter to the European Central Bank (ECB), for example, are those representing half a billion people. The ECB is concerned with the inflation or unemployment rate across the eurozone as if it were a single homogeneous territory, at the same time as the economic fate of European citizens is splintering in different directions, depending on which region, city or neighbourhood they happen to live in. Official knowledge becomes ever more abstracted from lived experience, until that knowledge simply ceases to be relevant or credible.
The privileging of the nation as the natural scale of analysis is one of the inbuilt biases of statistics that years of economic change has eaten away at. Another inbuilt bias that is coming under increasing strain is classification. Part of the job of statisticians is to classify people by putting them into a range of boxes that the statistician has created: employed or unemployed, married or unmarried, pro-Europe or anti-Europe. So long as people can be placed into categories in this way, it becomes possible to discern how far a given classification extends across the population.
This can involve somewhat reductive choices. To count as unemployed, for example, a person has to report to a survey that they are involuntarily out of work, even if it may be more complicated than that in reality. Many people move in and out of work all the time, for reasons that might have as much to do with health and family needs as labour market conditions. But thanks to this simplification, it becomes possible to identify the rate of unemployment across the population as a whole.
Here’s a problem, though. What if many of the defining questions of our age are not answerable in terms of the extent of people encompassed, but the intensity with which people are affected? Unemployment is one example. The fact that Britain got through the Great Recession of 2008-13 without unemployment rising substantially is generally viewed as a positive achievement. But the focus on “unemployment” masked the rise of underemployment, that is, people not getting a sufficient amount of work or being employed at a level below that which they are qualified for. This currently accounts for around 6% of the “employed” labour force. Then there is the rise of the self-employed workforce, where the divide between “employed” and “involuntarily unemployed” makes little sense.
This is not a criticism of bodies such as the Office for National Statistics (ONS), which does now produce data on underemployment. But so long as politicians continue to deflect criticism by pointing to the unemployment rate, the experiences of those struggling to get enough work or to live on their wages go unrepresented in public debate. It wouldn’t be all that surprising if these same people became suspicious of policy experts and the use of statistics in political debate, given the mismatch between what politicians say about the labour market and the lived reality.
The rise of identity politics since the 1960s has put additional strain on such systems of classification. Statistical data is only credible if people will accept the limited range of demographic categories that are on offer, which are selected by the expert not the respondent. But where identity becomes a political issue, people demand to define themselves on their own terms, where gender, sexuality, race or class is concerned.
Opinion polling may be suffering for similar reasons. Polls have traditionally captured people’s attitudes and preferences, on the reasonable assumption that people will behave accordingly. But in an age of declining political participation, it is not enough simply to know which box someone would prefer to put an “X” in. One also needs to know whether they feel strongly enough about doing so to bother. And when it comes to capturing such fluctuations in emotional intensity, polling is a clumsy tool.
Statistics have faced criticism regularly over their long history. The challenges that identity politics and globalisation present to them are not new either. Why then do the events of the past year feel quite so damaging to the ideal of quantitative expertise and its role in political debate?
In recent years, a new way of quantifying and visualising populations has emerged that potentially pushes statistics to the margins, ushering in a different era altogether. Statistics, collected and compiled by technical experts, are giving way to data that accumulates by default, as a consequence of sweeping digitisation. Traditionally, statisticians have known which questions they wanted to ask regarding which population, then set out to answer them. By contrast, data is automatically produced whenever we swipe a loyalty card, comment on Facebook or search for something on Google. As our cities, cars, homes and household objects become digitally connected, the amount of data we leave in our trail will grow even greater. In this new world, data is captured first and research questions come later.
In the long term, the implications of this will probably be as profound as the invention of statistics was in the late 17th century. The rise of “big data” provides far greater opportunities for quantitative analysis than any amount of polling or statistical modelling. But it is not just the quantity of data that is different. It represents an entirely different type of knowledge, accompanied by a new mode of expertise.
First, there is no fixed scale of analysis (such as the nation) nor any settled categories (such as “unemployed”). These vast new data sets can be mined in search of patterns, trends, correlations and emergent moods. It becomes a way of tracking the identities that people bestow upon themselves (such as “#ImwithCorbyn” or “entrepreneur”) rather than imposing classifications upon them. This is a form of aggregation suitable to a more fluid political age, in which not everything can be reliably referred back to some Enlightenment ideal of the nation state as guardian of the public interest.
Second, the majority of us are entirely oblivious to what all this data says about us, either individually or collectively. There is no equivalent of an Office for National Statistics for commercially collected big data. We live in an age in which our feelings, identities and affiliations can be tracked and analysed with unprecedented speed and sensitivity – but there is nothing that anchors this new capacity in the public interest or public debate. There are data analysts who work for Google and Facebook, but they are not “experts” of the sort who generate statistics and who are now so widely condemned. The anonymity and secrecy of the new analysts potentially makes them far more politically powerful than any social scientist.
A company such as Facebook has the capacity to carry quantitative social science on hundreds of billions of people, at very low cost. But it has very little incentive to reveal the results. In 2014, when Facebook researchers published results of a study of “emotional contagion” that they had carried out on their users – in which they altered news feeds to see how it affected the content that users then shared in response – there was an outcry that people were being unwittingly experimented on. So, from Facebook’s point of view, why go to all the hassle of publishing? Why not just do the study and keep quiet?
What is most politically significant about this shift from a logic of statistics to one of data is how comfortably it sits with the rise of populism. Populist leaders can heap scorn upon traditional experts, such as economists and pollsters, while trusting in a different form of numerical analysis altogether. Such politicians rely on a new, less visible elite, who seek out patterns from vast data banks, but rarely make any public pronouncements, let alone publish any evidence. These data analysts are often physicists or mathematicians, whose skills are not developed for the study of society at all. This, for example, is the worldview propagated by Dominic Cummings, former adviser to Michael Gove and campaign director of Vote Leave. “Physics, mathematics and computer science are domains in which there are real experts, unlike macro-economic forecasting,” Cummings has argued.
Figures close to Donald Trump, such as his chief strategist Steve Bannon and the Silicon Valley billionaire Peter Thiel, are closely acquainted with cutting-edge data analytics techniques, via companies such as Cambridge Analytica, on whose board Bannon sits. During the presidential election campaign, Cambridge Analytica drew on various data sources to develop psychological profiles of millions of Americans, which it then used to help Trump target voters with tailored messaging.
This ability to develop and refine psychological insights across large populations is one of the most innovative and controversial features of the new data analysis. As techniques of “sentiment analysis”, which detect the mood of large numbers of people by tracking indicators such as word usage on social media, become incorporated into political campaigns, the emotional allure of figures such as Trump will become amenable to scientific scrutiny. In a world where the political feelings of the general public are becoming this traceable, who needs pollsters?
Few social findings arising from this kind of data analytics ever end up in the public domain. This means that it does very little to help anchor political narrative in any shared reality. With the authority of statistics waning, and nothing stepping into the public sphere to replace it, people can live in whatever imagined community they feel most aligned to and willing to believe in. Where statistics can be used to correct faulty claims about the economy or society or population, in an age of data analytics there are few mechanisms to prevent people from giving way to their instinctive reactions or emotional prejudices. On the contrary, companies such as Cambridge Analytica treat those feelings as things to be tracked.
But even if there were an Office for Data Analytics, acting on behalf of the public and government as the ONS does, it is not clear that it would offer the kind of neutral perspective that liberals today are struggling to defend. The new apparatus of number-crunching is well suited to detecting trends, sensing the mood and spotting things as they bubble up. It serves campaign managers and marketers very well. It is less well suited to making the kinds of unambiguous, objective, potentially consensus-forming claims about society that statisticians and economists are paid for.
In this new technical and political climate, it will fall to the new digital elite to identify the facts, projections and truth amid the rushing stream of data that results. Whether indicators such as GDP and unemployment continue to carry political clout remains to be seen, but if they don’t, it won’t necessarily herald the end of experts, less still the end of truth. The question to be taken more seriously, now that numbers are being constantly generated behind our backs and beyond our knowledge, is where the crisis of statistics leaves representative democracy.
On the one hand, it is worth recognising the capacity of long-standing political institutions to fight back. Just as “sharing economy” platforms such as Uber and Airbnb have recently been thwarted by legal rulings (Uber being compelled to recognise drivers as employees, Airbnb being banned altogether by some municipal authorities), privacy and human rights law represents a potential obstacle to the extension of data analytics. What is less clear is how the benefits of digital analytics might ever be offered to the public, in the way that many statistical data sets are. Bodies such as the Open Data Institute, co-founded by Tim Berners-Lee, campaign to make data publicly available, but have little leverage over the corporations where so much of our data now accumulates. Statistics began life as a tool through which the state could view society, but gradually developed into something that academics, civic reformers and businesses had a stake in. But for many data analytics firms, secrecy surrounding methods and sources of data is a competitive advantage that they will not give up voluntarily.
A post-statistical society is a potentially frightening proposition, not because it would lack any forms of truth or expertise altogether, but because it would drastically privatise them. Statistics are one of many pillars of liberalism, indeed of Enlightenment. The experts who produce and use them have become painted as arrogant and oblivious to the emotional and local dimensions of politics. No doubt there are ways in which data collection could be adapted to reflect lived experiences better. But the battle that will need to be waged in the long term is not between an elite-led politics of facts versus a populist politics of feeling. It is between those still committed to public knowledge and public argument and those who profit from the ongoing disintegration of those things.
Olivia Solon and Sam Levin in The Guardian
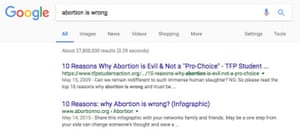
Google’s search algorithm appears to be systematically promoting information that is either false or slanted with an extreme rightwing bias on subjects as varied as climate change and homosexuality.
Following a recent investigation by the Observer, which uncovered that Google’s search engine prominently suggests neo-Nazi websites and antisemitic writing, the Guardian has uncovered a dozen additional examples of biased search results.
Google’s search algorithm and its autocomplete function prioritize websites that, for example, declare that climate change is a hoax, being gay is a sin, and the Sandy Hook mass shooting never happened.
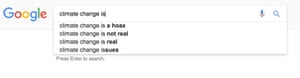
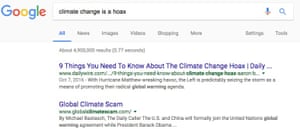
The increased scrutiny on the algorithms of Google – which removed antisemitic and sexist autocomplete phrases after the recent Observer investigation – comes at a time of tense debate surrounding the role of fake news in building support for conservative political leaders, particularly US President-elect Donald Trump.
Facebook has faced significant backlash for its role in enabling widespread dissemination of misinformation, and data scientists and communication experts have argued that rightwing groups have found creative ways to manipulate social media trends and search algorithms.

Google alters search autocomplete to remove 'are Jews evil' suggestion
The Guardian’s latest findings further suggest that Google’s searches are contributing to the problem.
In the past, when a journalist or academic exposes one of these algorithmic hiccups, humans at Google quietly make manual adjustments in a process that’s neither transparent nor accountable.
At the same time, politically motivated third parties including the ‘alt-right’, a far-right movement in the US, use a variety of techniques to trick the algorithm and push propaganda and misinformation higher up Google’s search rankings.
These insidious manipulations – both by Google and by third parties trying to game the system – impact how users of the search engine perceive the world, even influencing the way they vote. This has led some researchers to study Google’s role in the presidential election in the same way that they have scrutinized Facebook.
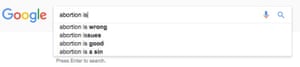
Robert Epstein from the American Institute for Behavioral Research and Technology has spent four years trying to reverse engineer Google’s search algorithms. He believes, based on systematic research, that Google has the power to rig elections through something he calls the search engine manipulation effect (SEME).
Epstein conducted five experiments in two countries to find that biased rankings in search results can shift the opinions of undecided voters. If Google tweaks its algorithm to show more positive search results for a candidate, the searcher may form a more positive opinion of that candidate.
In September 2016, Epstein released findings, published through Russian news agency Sputnik News, that indicated Google had suppressed negative autocomplete search results relating to Hillary Clinton.
“We know that if there’s a negative autocomplete suggestion in the list, it will draw somewhere between five and 15 times as many clicks as a neutral suggestion,” Epstein said. “If you omit negatives for one perspective, one hotel chain or one candidate, you have a heck of a lot of people who are going to see only positive things for whatever the perspective you are supporting.”
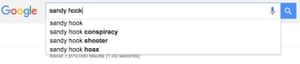
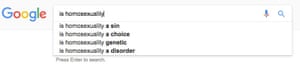
Even changing the order in which certain search terms appear in the autocompleted list can make a huge impact, with the first result drawing the most clicks, he said.
At the time, Google said the autocomplete algorithm was designed to omit disparaging or offensive terms associated with individuals’ names but that it wasn’t an “exact science”.
Then there’s the secret recipe of factors that feed into the algorithm Google uses to determine a web page’s importance – embedded with the biases of the humans who programmed it. These factors include how many and which other websites link to a page, how much traffic it receives, and how often a page is updated. People who are very active politically are typically the most partisan, which means that extremist views peddled actively on blogs and fringe media sites get elevated in the search ranking.
“These platforms are structured in such a way that they are allowing and enabling – consciously or unconsciously – more extreme views to dominate,” said Martin Moore from Kings College London’s Centre for the Study of Media, Communication and Power.
Appearing on the first page of Google search results can give websites with questionable editorial principles undue authority and traffic.
“These two manipulations can work together to have an enormous impact on people without their knowledge that they are being manipulated, and our research shows that very clearly,” Epstein said. “Virtually no one is aware of bias in search suggestions or rankings.”
This is compounded by Google’s personalization of search results, which means different users see different results based on their interests. “This gives companies like Google even more power to influence people’s opinions, attitudes, beliefs and behaviors,” he said.
Epstein wants Google to be more transparent about how and when it manually manipulates the algorithm.
“They are constantly making these adjustments. It’s absurd for them to say everything is automated,” he said. Manual removals from autocomplete include “are jews evil” and “are women evil”. Google has also altered its results so when someone searches for ways to kill themselves they are shown a suicide helpline.
Shortly after Epstein released his research indicating the suppression of negative autocomplete search results relating to Clinton, which he credits to close ties between the Clinton campaign and Google, the search engine appeared to pull back from such censorship, he said. This, he argued, allowed for a flood of pro-Trump, anti-Clinton content (including fake news), some of which was created in retaliation to bubble to the top.
“If I had to do it over again I would not have released those data. There is some indication that they had an impact that was detrimental to Hillary Clinton, which was never my intention.”
Rhea Drysdale, the CEO of digital marketing company Outspoken Media, did not see evidence of pro-Clinton editing by Google. However, she did note networks of partisan websites – disproportionately rightwing – using much better search engine optimization techniques to ensure their worldview ranked highly.
Meanwhile, tech-savvy rightwing groups organized online and developed creative ways to control and manipulate social media conversations through mass actions, said Shane Burley, a journalist and researcher who has studied the alt-right.
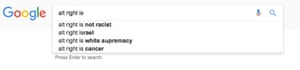
“What happens is they can essentially jam hashtags so densely using multiple accounts, they end up making it trending,” he said. “That’s a great way for them to dictate how something is going to be covered, what’s going to be discussed. That’s helped them reframe the discussion of immigration.”
Burley noted that “cuckservative” – meaning conservatives who have sold out – is a good example of a term that the alt-right has managed to popularize in an effective way. Similarly if you search for “feminism is...” in Google, it autocompletes to “feminism is cancer”, a popular rallying cry for Trump supporters.
“It has this effect of making certain words kind of like magic words in search algorithms.”
The same groups – including members of the popular alt-right Reddit forum The_Donald – used techniques that are used by reputation management firms and marketers to push their companies up Google’s search results, to ensure pro-Trump imagery and articles ranked highly.
“Extremists have been trying to play Google’s algorithm for years, with varying degrees of success,” said Brittan Heller, director of technology and society at the Anti-Defamation League. “The key has traditionally been connected to influencing the algorithm with a high volume of biased search terms.”
The problem has become particularly challenging for Google in a post-truth era, where white supremacist websites may have the same indicator of “trustworthiness” in the eyes of Google as other websites high in the page rank.
“What does Google do when the lies aren’t the outliers any more?” Heller said.
“Previously there was the assumption that everything on the internet had a glimmer of truth about it. With the phenomenon of fake news and media hacking, that may be changing.”
A Google spokeswoman said in a statement: “We’ve received a lot of questions about autocomplete, and we want to help people understand how it works: Autocomplete predictions are algorithmically generated based on users’ search activity and interests. Users search for such a wide range of material on the web – 15% of searches we see every day are new. Because of this, terms that appear in Autocomplete may be unexpected or unpleasant. We do our best to prevent offensive terms, like porn and hate speech, from appearing, but we don’t always get it right. Autocomplete isn’t an exact science and we’re always working to improve our algorithms.”
Nick Cohen in The Guardian
Donald Trump’s tax affairs are as nothing compared to those of the great global corporations

Keeping it offshore: Jost Van Dyke in the British Virgin Islands, a tax haven for the world’s rich. Photograph: Alamy
Donald Trump is offering himself as president of a country whose federal income taxes he gives every appearance of dodging. He says he is fit to be commander in chief, after avoiding giving a cent more than he could towards the wages of the troops who must fight for him. He laments an America where “our roads and bridges are falling apart, our airports are in third world condition and 43 million Americans are on food stamps”, while striving tirelessly to avoid paying for one pothole to be mended or mouth to be filled.
Men’s lies reveal more about them than their truths. For years, Trump promoted the bald, racist lie that Barack Obama was born in Kenya and, as an unAmerican, was disqualified from holding the presidency. We should have guessed then. We should have known that Trump’s subconscious was trying to hide the fact that he was barely an American citizen at all.
He would not contribute to his country or play his part in its collective endeavours. Like a guest in a hotel who runs off leaving the bill, Trump wanted to enjoy the room service without paying for the room. You should never lose your capacity to be shocked, especially in 2016 when the shocking has become commonplace. The New York Times published a joint piece last week by former White House ethics advisers – one to George W Bush and one to Barack Obama, so no one could accuse the paper of bias. They were stunned.
No president would have nominated Trump for public office, they said. If one had, “explaining to the senate and to the American people how a billionaire could have a $916m ‘loss carry-forward’ that potentially allowed him to not pay taxes for perhaps as long as 18 years would have been far too difficult for the White House when many hard-working Americans turn a third or more of their earnings over to the government”.
Trump’s bragging about the humiliations he inflicts on women is shocking. Trump’s oxymoronic excuses about his “fiduciary duty” to his businesses to pay as little personal tax as he could are shocking. (No businessman has a corporate “fiduciary duty” to enrich himself rather than his company.) Never let familiarity dilute your contempt.
And yet looked at from another angle, Trump is not so shocking. You may be reading this piece online after clicking on a Facebook link. If you are in Britain, the profits from the adverts Facebook hits you with will be logged in Ireland, which required Facebook to pay a mere €3.4m in corporate taxes last year on revenues of €4.83bn . If you are reading on an Apple device, Apple has booked $214.9bn offshore to avoid $65.4bn in US taxes. They are hardly alone. One recent American study found that 367 of the Fortune 500 operate one or more subsidiaries in tax havens.
Trump may seem a grotesque and alien figure, but his values are all around you. The Pepsi in your hand, the iPhone in your pocket, the Google search engine you load and the Nike trainers you put on your feet come from a tax-exempt economy, which expects you to pick up the bills.
The short answer to Conservatives who say “their behaviour is legal” is that it is a scandal that it is legal. The long answer is to invite them to look at the state of societies where Trumpian economics have taken hold. If they live in Britain or America, they should not have to look far.
The story liberal capitalism tells itself is heroic. Bloated incumbent businesses are overthrown by daring entrepreneurs. They outwit the complacent and blundering old firms and throw them from their pinnacles. They let creative destruction rip through the economy and bring new products and jobs with it.
If that justification for free-market capitalism was ever true, it is not true now. The free market in tax, it turns out, allows firms to move offshore and leave stagnant economies behind. Giant companies are no longer threatened by buccaneering entrepreneurs and innovative small businesses. Indeed, they don’t appear to be threatened by anyone.
The share of nominal GDP generated by the Fortune 100 biggest American companies rose from 33% of GDP in 1994 to 46% in 2013, the Economist reported. Despite all the fuss about tech entrepreneurship, the number of startups is lower than at any time since the late 1970s. More US companies now die than are born.
For how can small firms, which have to pay tax, challenge established giants that move their money offshore? They don’t have lobbyists. They can’t use a small part of their untaxed profits to make the campaign donations Google and the other monopolistic firms give to keep the politicians onside.
John Lewis has asked our government repeatedly how it can be fair to charge the partnership tax while allowing its rival Amazon to run its business through Luxembourg. A more pertinent question is why any government desperate for revenue would want a system that gave tax dodgers a competitive advantage.
What applies to businesses applies to individuals. The tax take depends as much on national culture as the threat of punishment, on what economists call “tax morale”.
No one likes paying taxes, but in northern European and North American countries most thought that they should pay them. Maybe I have lived a sheltered life, but I have no more heard friends discuss how they cheat the taxman than I have heard them discuss how they masturbate. If they cheat, they keep their dirty secrets to themselves. Let tax morale collapse, let belief in the integrity of the system waver, however, and states become like Greece, where everyone who can evade tax does.
The surest way to destroy morale is to make the people who pay taxes believe that the government is taking them for fools by penalising them while sparing the wealthy.
Theresa May promised at the Conservative party conference that “however rich or powerful – you have a duty to pay your tax”.
I would have been more inclined to believe her if she had promised, at this moment of asserting sovereignty, to close the British sovereign tax havens of the Channel Islands, Isle of Man, Bermuda and the British Virgin and Cayman Islands.
But let us give the new PM time to prove herself. If she falters, she should consider this. Revenue & Customs can only check 4% of self-assessment tax returns. If the remaining 96% decide that if Trump and his kind can cheat, they can cheat too, she would not be able to stop them.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}